JsPspEmu: New added optimizations
PSPEMU ARTICLE
May 3, 2015
I have already done some optimizations I planed some time ago.
Now the compiler is creating bigger functions. Also I have reduced the native function calling overhead, and the overhead of function lookup.
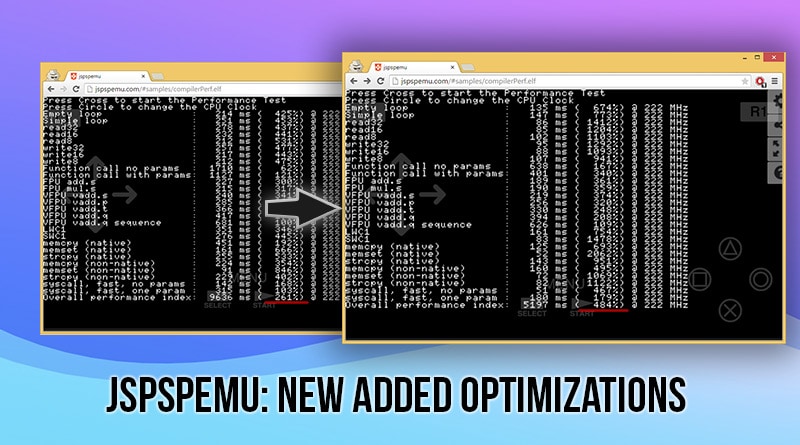
Here the results:
Loops and function calls are now much much faster than before, and that will mean faster running. In chrome the improvement is not that huge like with firefox. Firefox was performing so bad because of the function lookup that was lightning fast in chrome. Now that the function lookup is cached and not that frequent, there is not so much difference between chrome and firefox (regarding to cpu). Still the overall chrome is faster than firefox.
Also I have added a new benchmark with this (the v2): http://benchmark.jspspemu.com/v2/ You can still access the previous (v1): http://benchmark.jspspemu.com/v1/
And functions are something like this:
function(args) {
return function func_0x088042e4(state) {
"use strict";
var label = 0,
BRANCHPC = 0,
BRANCHFLAG = false,
memory = state.memory,
gpr = state.gpr,
gpr_f = state.gpr_f;
label = 0;
loop_label: while (true) switch (label) {
case 0:
case 1:
gpr[2] = 0x000f0000; /* lui */
gpr[2] = (gpr[2] | 0x00004240); /* ori */
gpr[4] = (0 + 0); /* addu */
gpr[5] = (0 + 50); /* addiu */
gpr[3] = (gpr[2] + 0); /* addu */
case 2:
gpr[4] = (gpr[4] + gpr[3]); /* addu */
case 3: //
while (true) { //
gpr[3] = (gpr[3] + -1); /* addiu */ //
BRANCHFLAG = (gpr[3] > 0); //
BRANCHPC = 0x088042fc; /* bgtzl */ //
if (BRANCHFLAG) { //
gpr[4] = (gpr[4] + gpr[3]); /* addu */ //
}; //
if (!(BRANCHFLAG)) break; //
} //
case 4:
if (BRANCHFLAG) {
label = 3;
continue loop_label;
}
case 5:
gpr[5] = (gpr[5] + -1); /* addiu */
BRANCHFLAG = (gpr[5] > 0);
BRANCHPC = 0x088042f8; /* bgtzl */
if (BRANCHFLAG) {
gpr[3] = (gpr[2] + 0); /* addu */
};
case 6:
if (BRANCHFLAG) {
label = 2;
continue loop_label;
}
case 7:
gpr[2] = 0x08810000; /* lui */
memory.sw(((gpr[2] + 17204) | 0), gpr[4]); /* sw */
state.PC = state.gpr[31];
state.jumpCall = null;
return;
break loop_label;
}
state.jumpCall = null;
return;
}
})
I have tried to use relooper to improve generated code a lot, but failed in some cases. So I put my own simple code generator. At least for the moment. It has an identical api like relooper, so it is easy to switch.
It performs a single while simple optimization for memory copying and so. The rest of the function uses a state machine. It has still a lot of space for optimizations. We can change gpr[] to normal state fields, and also we can allocate local variables. That would require updating the engine to provide information about used and writted registers in simple blocks. Also branchflag could be removed.
Function calling works like this:
function(args
/**/
) {
return function func_0x08804514(state) {
"use strict";
var label = 0,
BRANCHPC = 0,
BRANCHFLAG = false,
memory = state.memory,
gpr = state.gpr,
gpr_f = state.gpr_f;
label = 0;
loop_label: while (true) switch (label) {
case 0:
case 1:
gpr[29] = (gpr[29] + -8); /* addiu */
memory.sw(((gpr[29] + 4) | 0), gpr[31]); /* sw */
state.PC = 0x088044b8;
var expectedRA = state.RA = 0x08804524;
/* sll */
;
args.cache_0x088044b8.execute(state);
while ((state.PC != expectedRA) && (state.jumpCall != null)) state.jumpCall.execute(state);
if (state.PC != expectedRA) {
state.jumpCall = null;
return;
}
state.PC = 0x088044b8;
var expectedRA = state.RA = 0x0880456c;
/* sll */
;
args.cache_0x088044b8.execute(state);
while ((state.PC != expectedRA) && (state.jumpCall != null)) state.jumpCall.execute(state);
if (state.PC != expectedRA) {
state.jumpCall = null;
return;
}
debugger; // dbreak
/* dbreak */
gpr[31] = memory.lw(((gpr[29] + 4) | 0)); /* lw */
break loop_label;
}
state.jumpCall = null;
return;
}
})
I am generating a function, that ends generating the final function. The first function receives some constant non numeric/string values, like function references. Also allows to store cache values in there for several jalr.
After the call it checks if a jumpCall is != null, that’s because I’m simulating jumps by returning a function that is called by the callee (until browsers implements tail call optimization, then it will be just a call + an immediate return and it will be much faster, because i will be able to remove all the boilerplate code). This is called trampoline.
Also I have started to do some multithreading besides atrac3+ decoding that was already done in a webworker. Now I am inflating zlib/deflate in a worker, that includes decompressing zip files and cso files.
Also, promises were making everything slow because it queued to the next frame so chaining promises was slow as hell, so I implemented new promises and queued resolves immediately using Microtask. Now more things get smooth, and with less load times. Doom demo now starts a lot faster.
Probably now it would be a good moment to improve GPU rendering. Making it multithreaded, try to use SIMD and converting GPU commands to intermediate commands. There are a lot of things to do there. Like allocating elements in atlas to reduce batchcounts and so on.
Comments
Comments are powered by GitHub via utteranc.es.