pspemu (VI)
D PSPEMU
April 1, 2010
r99 -> r110. A few days later, at a slower place; no rush, but no stop.
- Major component refactoring. Partial code cleanup.
IoFileMgrForKernelfixes. A thing that prevented some games from work wasIoFileMgrForKernel, it was creatingStreamsin order to open files and was passing them to the virtual machine as a host machine pointer, the guest was taking it as an integer identifier. Pointer was lost from the host's heap and since the value was stored in a memory zone not controlled by the GC and bit being handled, when the GC was being executed, the still in use streams were collected. The solution was to store a list of opened Streams in the GC-controlled zone. I continued to pass pointers, but at least they were not collected. But what I will do in a future will be to create IDs that under the hood have pointers assigned. This way is more controllable and more similar to the original approach (with small ID values). With this change, Trigonometry Wars started to work.- Added a
sceRegmodule to handle the PSP register and added a pair of fake keys to the register to check it was working just fine. It is still not fully implemented, and it doesn't store the register's state, it doesn't even load the file registry, but allows to obtain registry keys that was the first approach to do some tests on some homebrews. - Disabled temporarily audio threads; they were slowing things down a lot, since sound is not working properly yet. I have to make a mixer or to use one already created (like fmod for example).
- Implemented a few more kernel modules.
- Improved error handling and the debug information being shown, though still there is no a proper graphic debugger.
- I mede minor
ThreadManForUseradjustments si thepspsolitairecan start. Threads are one of the aspects that are breaking more things. Until they are correctly implemented, there will be problems everywhere. - I added a
Loggerclass, to not depend on the console when working on the GUI, and to be able to filter certain logs. - Tests were broken since a lot of revisions, so I started to fix it again. Restructured syscalls;
I changed their codes from >= 0x2000 to >= 0x1000 since PSP is not reserving those codes for kernel functions and it is "safer".
Added a new syscall to specify a memory range to do a CRC32 to verify that the content was the expected.
Prepared an executable that would launch tests searching for
.expectedfiles. - Starteed a hexadecimal editor component to view and edit the guest memory.
- Added a CLOCK register per thread incrementng it for each executed instruction.
- Added a JAL and JR r31 debugger, to being able to locate problems easier.
- Starteed to implement support for relocatable
Elffiles. - Fixed a couple of graphic problems: transform2D 480 -> 512 for glOrtho (this made that some pixels were dropped on the right part of the screen on some 2D games); glReadPixels in gpu.impl.GpuOpengl (made that there were problems when rendering using GE in non-RGBA8888 targets).
- Made changes to the assembler. Added support to the emulator to load, assemble and execute mips assembly directly. This would allow me to create very simple assembler tests to try instructions individually. Created a demo in assembler with a very few instructions (12 more or less) to try out the performance. Even being 12 instructions, it made a pretty costly process, that was to fill the whole displayBuffer (0x04000000-0x04088000) from a single color that was changing (not full pixels), but component by component. This is more or less half-million of iterations. And since each iteration has several instructions, in interpreter mode it was being executed at 6fps approximately.
- This was a prelude of what I wanted to do. I wanted to start dynamic recompilation. And at 6-oclock of today, that assembler example is working at 50fps and without too much optimizations :P. This is about 8x times the speed in interpreted mode.
- Working on my laptop, that is already a bit old, implies to have less execution power. This has some advantages: it allows me to see things that are slow and to try to make them faster. The bad part: I waste much more time; programs that stop working after some time, or the time I have to spend compiling, is wasted time. I have to try DSSS to see if compiling time improves substantially.
Things to comment:
The most interesting part has been dynamic recompilation. It was a first approach. Even if I have done some dynarec tech demos in D, it was pretty simple and not very realistic.
About how it works:
It is done in layer. This first layer there is a code emission that it is not targeting any host or guest platform. This first layer is in charge of offering a serie of functions to write to an buffer (that will be able to execute) with values of 8, 16 and 32 bits. It is also in charge of creating labels, and slots referencing labels, and the possibility to write to slots once the labels have been defined. It allows to write relative and absoluet 32 bits addresses. After that I worked on another layer above that it is focused on generating host X86 code to 32-bit execution. It offers a set of limited functions to generate code. (I'm adding more as needed).
After that I added another layer focused on the MIPS guest. Basically it offers a set of functions that emit 8086 code based on the MIPS characteristics.
Basic operation:
Regarding to the MIPS registers and ABI: PCs have 8 registers of "general" usage (though certain instructions are being for specific purposes). Some registers have to be preserved between functions, as specified in the X86 convention calls:
http://en.wikipedia.org/wiki/X86_calling_conventions
EAX, EDX and ECX can be freely used without having to preserve its original values for callers. So I decided to start using these manily at a first moment, to avoid to have to handle PUSHes and POPs or to store registers and restore them in other memory zones.
Since you cannot map 8 registers to 32, the simplest implementation is to work on pointers where you have registers and to use the cool direct memory access from X86.
I decided to use the ECX register to store the pointer to the MIPs registers. So the first thing done before starting to execute code is to place on ECX the pointer to the registers.
After this the normal operations consists in store/load values from MIPS registers in EAX and EDX to do the right operation and to store the output on the right MIPS register using ECX as base.
The other complicated part is to handle jumps (specially since MIPs have delayed branches and likely instructions for later MIPS versions).
But in addition of all these, you have to handle thread switching and to handle interruptions "from time to time". Since we know that sooner or later our code will reach a branch or a jump, these are good points to do costly operations. Before jumps, I'm executing a call to a "tick" function in charge of doing those processing and to return true or false whether there have been a PC change or not. If it has been a PC change, we have to stop the execution and start over again. This also happens on syscalls, on jalr and on jr that have indeterminate directions when the code is recompiled.
Handling delayed branches:
One pretty characteristic feature of MIPs is delayed branches. In order to know how to implement them, first we need to know how it works. Simplifying, delayed branch makes the immediate next instruction of a branch to be executed after determining the jump. This is a bit numb since in X86 it doesn't work that way, so you have to sort things a bit.
It is not that much a problem by itself. But the main problem is that there are some "Likely" jump, whose instruction is only executed when the condition of the jump is true, if not, this is being skipped. This complicates things a bit.
The solution I have applied (though I'm still not fully confident about it since I have not checked other implementions), is to generate a code before and other later of the delayed slot depending on the jump instruction. In normal branches, you make the comparision before, store the comparison flags and if the operation in delayed slot modifies them and later yu perform the jump after executing the delayedd slow if the evaluated condition before is true regarding the jump kind.
I still have not implemented Likely, but it would require one more jump. Probably a conditional one to the next instruction to the delayed slot, and other inconditional between the delayed slot and the next instruction. It is a pain, but it is like this.
Function analysis, reusing generated code and cache:
Another complicated part is to handle and to analyze compiled blocks. On one hand you have to analyze the code that
is going to be executed searching for conditional and unconditional jumps that are the ones making the function
to end: J and JR.
Initially I did it other way, but since I had some problems, I ended creating a label for each compiled instruction and later to use references. Making it for each instruction, allows to make it in a single step (without needed to make an analysis stop to determine the labels, and other for the emission). On the one hand this will require more memory, and maybe when the compiled code is not there, it might require more time to compile. Though I don't believe this is the most important thing, since once compiled it should be pretty fast.
Another thing is that you have to select code blocks to execute.
The first thing you have to do when you want to execute a memory address, is to check if there is a compiled block containing that address. If you have it, you go to that block, locate the right label and start executing it. The supposed cost of it is two hashmap access (mostly logarithmic with a linear part for collisions). Maybe we could improve it, but that will happen later. At this point at least performance improves a lot.
If you cannot locate it (code cache miss), it starts the analysis process that generates a compiled block, and once it ends, you search again in the cache.
One thing that I have not done yet and that will be required for unittesting (and worked just fine in interpreted mode) was to invalidate code blocks. In certain situations the code can be modified (for example dynamic recompilation inside the host, or when dinamically loading libraries that occuppies the same memory address). You have to handle writes and if you change a cached part, you will have to invalidate it. I can think of a few ways of doing this pretty fast, but I will write about it in other moment once I implemented it.
And that's it. Nothing more to add at this point. This is the first time I start doing dynamic recompilation for the real, and I'm not fully sure if I have implemented it right. At any rate, I wanted to do a first try on my own, without taking advantage of errors learnt from other people so I can discover it by myself. Once it is working I will check other implementations to determine how are they doing it. Keeping the good things from my implementation, and the good things of the other implementations.
And that's it. Here are a few screenshots of homebrew games that started to work in the latest SVG versions:
http://pspemu.soywiz.com/screenshots
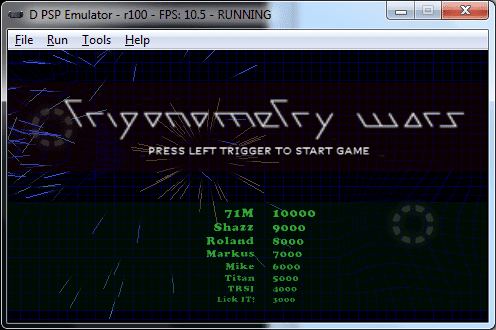
Trigonometry wars. Was the first homebrew game starteed to work. With the audio threads blocked, it works at a pretty decent speed on my laptop in interpreted mode.
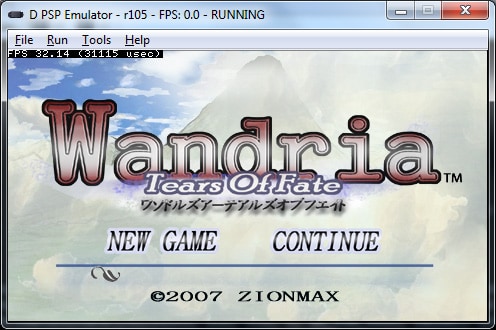
Gold Miner. A demo done probably in a summer contest at SangHai. It loads at a pretty good speed on my laptop.
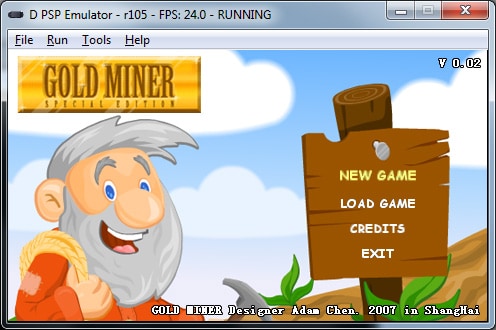
RPG Technical demo. Wandria: Tears of Fate. It takes a while to load in interpreted mode and after that you can reach between 10 and 35 fps on my laptop.
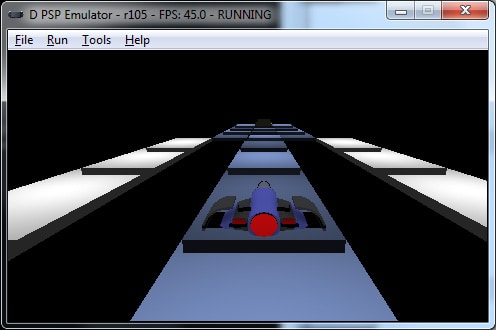
An initial SkyRoads port. This is 3D. It works pretty well on my laptop.
Spanish
r99 -> r110. Unos cuantos días después, a un ritmo mucho más relajado; sin prisa pero sin pausa.
- Refactorizaciones mayores en diferentes componentes. Limpieza parcial de código.
- Correcciones en IoFileMgrForKernel. Una cosa que impedía funcionar algunos juegos era que el IoFileMgrForKernel, creaba Streams a la hora de abrir archivos y se los pasaba a la máquina virtual como un puntero de la máquina host, que el guest tomaba como un identificador entero. El puntero se perdía de la heap del host y de las pilas y como el valor estaba guardado en una zona de memoria no controlada por el GC y que no se puede gestionar, cuando se ejecutaba el recolector de basura, se cargaba streams que todavía estaban en uso. La solución fue guardarse una lista de Streams abiertos en la zona controlada por el GC. Se seguía pasando el puntero, pero ya no se perdía. Aunque lo que haré en un futuro será crear IDs de valor bajo que tengan asignado el puntero. Así es más controlable y más cercano al comportamiento original. Con esto empezó a funcionar el Trigonometry Wars.
- Añadí el módulo sceReg para gestionar el registro de la psp y le añadí un par de claves fake al registro para probar que funcionaba. No está implementado todavía 100%, ni guarda el estado del registro, ni carga el registro de un archivo, pero permite obtener claves del registro que era la primera aproximación par a hacer pruebas con ciertos homebrew.
- Deshabilité temporalmente los threads de audio; ralentiazaban bastante todo, y actualmente el sonido no funciona correctamente. Tengo que hacer un mixer o usar uno ya hecho (como fmod por ejemplo).
- Implementé más métodos de diferentes módulos del kernel.
- Mejoré la gestión de errores y la información de debug que se muestra, aunque( todavía no hay un debugger gráfico en condiciones).
- Hice cambios menores ThreadManForUser para que arrancase pspsolitaire. Los threads suele ser uno de los aspectos que más cosas rompen. Hasta que estén correctamente implementados, habrán problemas por todas partes.
- Añadí una clase Logger por una parte para no depender de la consola cuando se trabaje más la GUI y por otra parte para poder filtrar a petición ciertos mensajes.
- El tema de tests estaba completamente roto desde hacía bastantes revisiones, así que me puse a apañarlo. Reestructuré las syscalls; les cambie los códigos de >= 0x2000 a >= 0x1000 ya que la PSP no reserva esos códigos para las funciones del kernel y es más "seguro". Añadí una syscall nueva para especificar un rango de memoria del que se hará un CRC32 para verificar que el contenido es el esperado. Preparé un ejecutable que lanzaría los tests buscando archivos .expected.
- Empecé un componente de edición hexadecimal para ver y editar la memoria del guest.
- Añadí un registro CLOCK por thread incrementado por cada instrucción ejecutada.
- Metí debugging de JAL y JR r31 para poder localizar problemas con mayor facilidad.
- Empecé la implementación de la relocalización de Elf relocalizables.
- Arreglé un par de problemas gráficos: transform2D 480 -> 512 for glOrtho (esto hacía que se "comiesen" algunos pixeles a la derecha en juegos con todo/parte en 2D); glReadPixels en gpu.impl.GpuOpengl (hacía que hubiesen problemas al renderizar mediante GE en targets que no fuesen RGBA8888).
- Hice cambios en el ensablador. Y añadí la posibilidad de que el emulador pudiese cargar, ensamblar y ejecutar ensamblador mips directamente. Esto permitiría crear tests muy sencillos en ensamblador para probar instrucciones individualmente. Creé una demo en ensamblador de unas pocas instrucciones (unas 12) para probar el rendimiento. Pese a ser 12 instrucciones, hacía un proceso muy costoso, que era pintar todo el displayBuffer (0x04000000-0x04088000) de un color que iba cambiando (y no pixel a pixel, sino componente a componente). Eso es mas o menos medio millón de iteraciones. Y cada iteración tiene varias instrucciones. En el modo intérprete esto iba a unos 6fps.
- Esto era el preludio de lo que quería hacer. Quería empezar ya la recompilación dinámica. Y a las 6 de la mañana de hoy he dejado el ejemplo en ensamblador sencillo que hice funcionando a rozando 50fps y sin hacer demasiadas optimizaciones :P. Esto es unas 8 veces la velocidad en modo intérprete.
- El hecho de estar trabajando en el portátil, en uno que ya tiene algún tiempo, implica tener menos potencia de ejecución. Esto tiene ventajas: me hace ver las cosas que van lentas y tratar de hacer que vayan más rápido. Desventajas: pierdo mucho más tiempo; los programas que "cascan" pasado un rato o el tiempo que invierto compilando, es tiempo perdido. Tengo que probar DSSS para ver si mejoro los tiempos de compilación sustancialmente.
Cosas a comentar:
Lo más interesante en este bloque de revisiones ha sido la recompilación dinámica. Era una primera aproximación. Si bien ya había hecho alguna demo técnica de recompilación dinámica en D, había sido muy sencilla y poco realista.
Sobre cómo está montado:
Está montado por capas. Hay una primera capa de un emisor de código que no se centra en ninguna plataforma host, ni en ninguna guest. Esta primera capa se encarga de ofrecer una serie de funciones para escribir en un buffer (que se podrá ejecutar) valores de 8, 16 y 32 bits. También se encarga de la creación de etiquetas y slots referenciando a etiquetas, y la posibilidad de escribir en los slots, una vez las etiquetas han sido definidas. Permite escrituras de 32 bits relativas y absolutas. Luego monté otra capa encima que ya se enfocaba en generación de código de host X86 para ejecución de 32 bits. Ofrece una serie de funciones limitadas para generación de código. (Voy añadiendo conforme me van haciendo falta.).
Luego monté una última capa enfocada al guest MIPS. Básicamente ofrece una serie de funciones que emiten código de 8086 en función de características del MIPS.
Funcionamiento básico:
El tema de los registros del mips. Los PCs tienen 8 registros de uso "general" (aunque para ciertas instrucciones son de uso específico). Algunos registros se tienen que preservar tras la ejecución de funciones, como se especifica en las convenciones de llamada de los X86:
http://en.wikipedia.org/wiki/X86_calling_conventions
EAX, EDX y ECX se pueden usar sin miedo a fastidiar valores usados en el ámbito superior. Así que decidí trabajar con esos principalmente, para evitar marrones de PUSHes y POPes o de guardar los registros y restaurarlos en alguna otra zona de memoria.
Como no se pueden mapear 8 registros en 32, la implementación más sencilla es trabajar con un puntero donde estén los registros y usar el acceso a memoria directo tan molón de los X86.
Decidí usar el registro ECX para almacenar el puntero a los registros. Así que lo primero que se hace antes de empezar ejecutar código es meter en ECX el puntero a los registros.
Después de esto las operaciones normales consisten en guardar/cargar valores de los registros de MIPS en EAX y EDX, hacer la operación pertinente y guardar en el registro de salida el valor, usando ECX como base.
Luego, al margen de los saltos que son la parte más complicada (especialmente por el delayed branch de los mips y el likely de las revisiones posteriories). Al margen de eso, hay que hacer switching de threads y gestionar interrupciones "cada cierto tiempo". Como sabemos que tarde o temprano el código llegará a un branch o un jump, por narices, pues los branches y los jumps son buenos momentos para hacer estas costosas gestiones. Antes de los saltos, hago una llamada a una función "tick" que se encarga de hacer estos procesos y devolver true o false dependiendo de si ha habido un cambio en PC. Si ha habido un cambio de PC, hay que salirse de la ejecución y volver a empezar. Esto ocurre también en las syscalls, en los jalr y en los jr que tienen direcciones indeterminadas cuando se recompila el código.
La gestión de los delayed branch:
Una características indentificativa de los MIPS son los delayed branch. Para saber cómo implementarlo primero hay que saber cómo funciona. Simplificando, la delayed branch tiene la característica de que la instrucción posterior a un salto, se ejecuta después de haber determinado el salto. Esto es un engorro ya que en X86 no hay nada parecido, con lo que hay que reordenar algunas cosas.
Esto en sí mismo no es "demasiado" follón. El problema es que hay ciertos saltos "Likely", cuya instrucción en el delayed slot se ejecuta únicamente si se va a realizar el salto, si no, se skippea. Esto complica un poco el tema.
La solución que he aplicado yo (que no tengo claro si es buena en comparación con otras porque todavía no he visto otras implementaciones), es generar un código antes y otro código después del delayed slot en función de la instrucción de salto. En los branches normales, se hace la comparación antes, se guardan los flags de comparación si la operación del delayed slot los modifica y luego se hace el salto después de haber ejecutado el delayed slot si la condición evaluada antes es cierta con respecto al tipo de salto.
Los Likely todavía no los he implementado, pero supondrán añadir un salto más. Posiblemente uno condicional a la siguiente instrucción al delayed slot, y otro incondicional entre el delayed slot y la instrucción siguiente. Es un coñazo sí, pero es lo que hay.
Análisis de funciones, reutilización de código compilado y caché:
La otra parte complicada es la gestión y análisis de bloques compilados. Por una parte hay que analizar el código que se va a ejecutar en busca de saltos condicionales y de saltos incondicionales que producen un callejón sin salida, que serán los puntos que hagan que la función de análisis termine: J, JR.
Inicialmente lo hice de otra forma, pero como me dio algunos problemas, acabé creando una etiqueta por cada instrucción compilada y luego usar referencias. Al hacerse por cada instrucción, se puede hacer en un solo paso (sin necesidad de un paso de análisis [para determinar las etiquetas] y otro de emisión) por contra debería ocupar más memoria y quizá cuando no esté compilado el código, le podría costar un poco más de compilar. Aunque creo que estos dos factores son los de menos, ya que una vez compilado es cuando el asunto vuelta.
El tema de selección de bloques de código a ejecutar.
Lo primero que se hace cuando se quiere empezar a ejecutar desde una posición de memoria, es mirar a ver si hay algún bloque compilado que contenga esa dirección. Si se contiene, va a ese bloque, se localiza la etiqueta y se empieza a ejecutar. Esto tiene actualmente un supuesto coste de dos accesos a un hashmap (2 veces logarítmico con una parte lineal para colisiones). Quizá se podría mejorar, pero eso será más adelante. Por lo pronto mejora mucho el rendimiento.
Si no se localiza (miss de caché de código), se empieza el proceso de análisis que genera un bloque compilado, y cuando se termina, se vuelve a buscar en la caché.
Una cosa que no he hecho todavía que habrá que hacer y para la que he preparado un unittesting (que se pasa sin problemas en la versión interpretada) es la invalidación de bloques. En determinadas ocasiones (por ejemplo recompilación dinámica en el guest o carga dinámica de librerías ocupando el mismo espacio de memoria), un código ejecutado puede modificarse. Hay que gestionar las escrituras y si se toca una parte cacheada invalidarla. Se me ocurre alguna forma de hacer esto relativamente bastante rápido, pero ya hablaré sobre el tema cuando llegue el momento.
Por lo demás nada más que añadir por el momento. El tema de la recompilación dinámica es la primera vez que lo hago en serio y no tengo claro si lo he hecho bien. Quería de todas formas hacer un primer intento a mi "bola", sin aprovechar los errores aprendidos por otras personas y queriendo descubrir cómo montarlo por mí mismo. Una vez esté funcionando miraré otras implementaciones para ver cómo lo han montado ellos y comparar. Quedarme con las cosas buenas de la mía, y con las cosas buenas de la otra/otras.
Y nada más. Aquí dejo algunos screenshots de algunos juegos homebrew que empiezan a funcionar con las últimas versiones del SVN:
http://pspemu.soywiz.com/screenshots
Trigonometry wars. Fue el primer juego homebrew en funcionar. Con los threads de audio bloqueados, va a una velocidad medianamente aceptable en mi portátil en modo intérprete.
Gold Miner. Una demo hecha posiblemente para algún concurso veraniego en SangHai. Carga y va a una velocidad bastante buena en mi portátil.
Demo técnica de rpg. Wandria: Tears of Fate. Le cuesta bastante cargar en modo intérprete y luego va entre 10 y 35 fps en mi portátil.
Un inicio de port del juego Skyroads. Este está en 3D. Va bastante bien en mi portátil.
Comments
Comments are powered by GitHub via utteranc.es.